January 29, 2016
By James Fryman
Originally published at http://devops.com/2016/01/29/unifying-applications-into-one-system
Let’s talk about a real problem that all of us have faced at one point or another: keeping track of a single thread of work across many disparate tools. Regardless of the specific industry a company operates in, as a company grows, back-office applications in support of the business begin to accumulate. Many knowledge based companies have some sort of communication tool, some sort of project tracker, and some support tracker. These are tools that aim at being more effective with daily business process. Conversations suffice until they do not, and tools are implemented as the need arises. Every tool that was added has purpose, solves a critical need, and made you and/or your team more productive.
At some point however, this changes. Discovery starts to become a major issue as usage patterns between different tools leaves solos of data. It becomes hard to correlate the different company pipelines that ultimately drive your business: the pipeline to care and communicate for customers, the pipeline to deliver new features, and the human interfaces involved in each. This is only intensified by team members that work on different project with different tools and people, you introduce team members from a timezone not your own, the sheer quantity of work… how many ways can you name how not just conversations are lost, but context
Commonly, teams attempt to solve this in a few ways:
At StackStorm, we ran into this problem. We have two ticketing systems (GitHub issues and Jira), a service desk tool (reamaze), and a chat client (Slack). The solution we use at StackStorm is one that I borrowed from my time at GitHub. One of my colleagues setup a really cool hook into Hubot that listened in our chat rooms for conversations we were having related to a GitHub Issue, a Pull Request, or even a code commit. When someone mentions one of these things, Hubot would grab a chat log plank, and cross-link the permalink to the Issue or Pull Request.
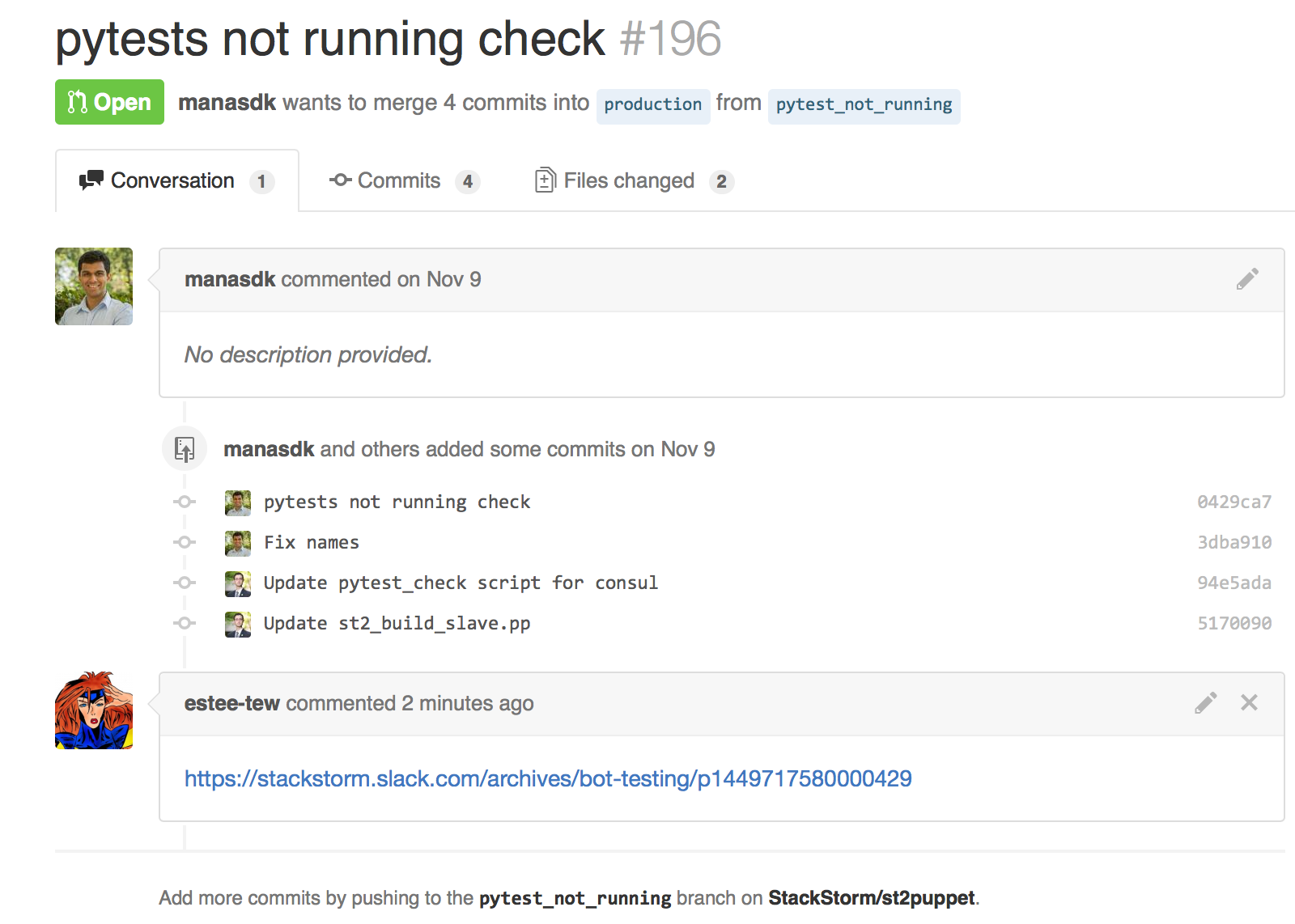
But, that’s just GitHub. Context matters across all tools, and gives team members additional flexibly in learning and gaining knowledge on their own. So, we took our Support Tool, reamaze, and did the same thing!
This is one part of a set of behaviors that helps create a dynamic web of information. By seamlessly having a mechanism to associate conversations and issues/pr/tickets/whatever, it becomes much easier to have conversations happen whenever they need to (serendipitous interactions ftw) and still get context to team members when they’re available.
This matters because: There is only one system.
Full disclosure: I am affiliated with StackStorm the company building StackStorm the tool. That being said, the ultimate goal here is to illustrate the pattern of how harness the recent chat culture change using an event-driven framework with the hopes of regaining just a modicum of sanity in your daily life. If you’re interested in learning more about StackStorm and how it ties into the overall automated troubleshooting and autoremeditaion space, take a look at our ChatOps Pitfalls and Tips by Dmitri Zimine. That should give you a good background on why we used StackStorm instead of say… just a small script.
Ok, on to business!
This workflow begins with a sensor. Inside of the StackStorm-Slack integration is a sensor class connects to the Slack Real-Time Messaging API. The first place to begin is with Sensors. The official Slack pack contains a sensor. This sensor uses the Slack RTM to connect to Slack and listen for messages in rooms that it is associated with. Each message is then sent as an “event” to StackStorm which I can create rules that will trap certain events and kick off.
Now that the sensor is emitting triggers into the system, I need to find a way to take an action when someone mentions an issue or ticket. The mechanism here is via a rule. Rules check triggers emitted into the system via sensors against a series of checks, and then executes an action or workflow if matched. A trigger can match to many rules.
Let’s create a rule to watch Slack for discussions related to reamaze
The first element in the criteria block is trigger.text. In the rule, the trigger itself is just referred to as trigger as opposed to slack.message.text. We want to see if the text propery contains a pattern related to our reamaze issue tracker. I chose contains out of the large list of comparison operators, and made sure the pattern matches what I’m looking for. Last but not least, the action block. This block is basically the next operation. Here, I can choose a single action or a workflow to kick off, and even grab data from the trigger payload to pass to the action. In this case, I opted to create a new workflow for my purposes here, and made sure to grab a few keywords that I needed to do processing.
At this point, I have a rule matching and now I need to create the action necessary to process the trigger.
Next, we get to creating the actions. The goal is to ensure that anytime a discussion randomly breaks out about a reamaze support ticket, that @estee-tew posts the Slack permalink to the support ticket. With the trigger payload extracted in the above rule, the workflow will need to:
Inside the reamaze pack, I can see that I have the ability to create_message. This action takes three parameters: slug, message, and visibility. In our rule above, the action that was kicked off when the critera matched desired slack messages is stackstorm.crosslink_slack_to_reamaze. As of right now, this does not exist, so that is the next step. For brevity’s sake, you can take a look at the action metadata on GitHub.
This is a simple Action Chain. In as much as it just does one task after another. The tasks here are designed to be small and portable so they can be re-used. Let’s quickly inspect each of the actions and walk through what it is that lies before us now.
The goal is to create a way to crosslink a Slack permalink, so let’s start there. This starts with the get_permalink action above. While the history permalink is not in the trigger payload (or even in the official API, for that matter), Slack permalinks are actually not too terribly difficult to figure out. The first action takes two parameters (channel and timestamp), and then spits us out our permalink. We know we’re going to publish the permalink variable that can now be globally used in the workflow in the future. In additon, the next step takes us to the sanitize_message task. You can take a look at the python code for this action upstream.
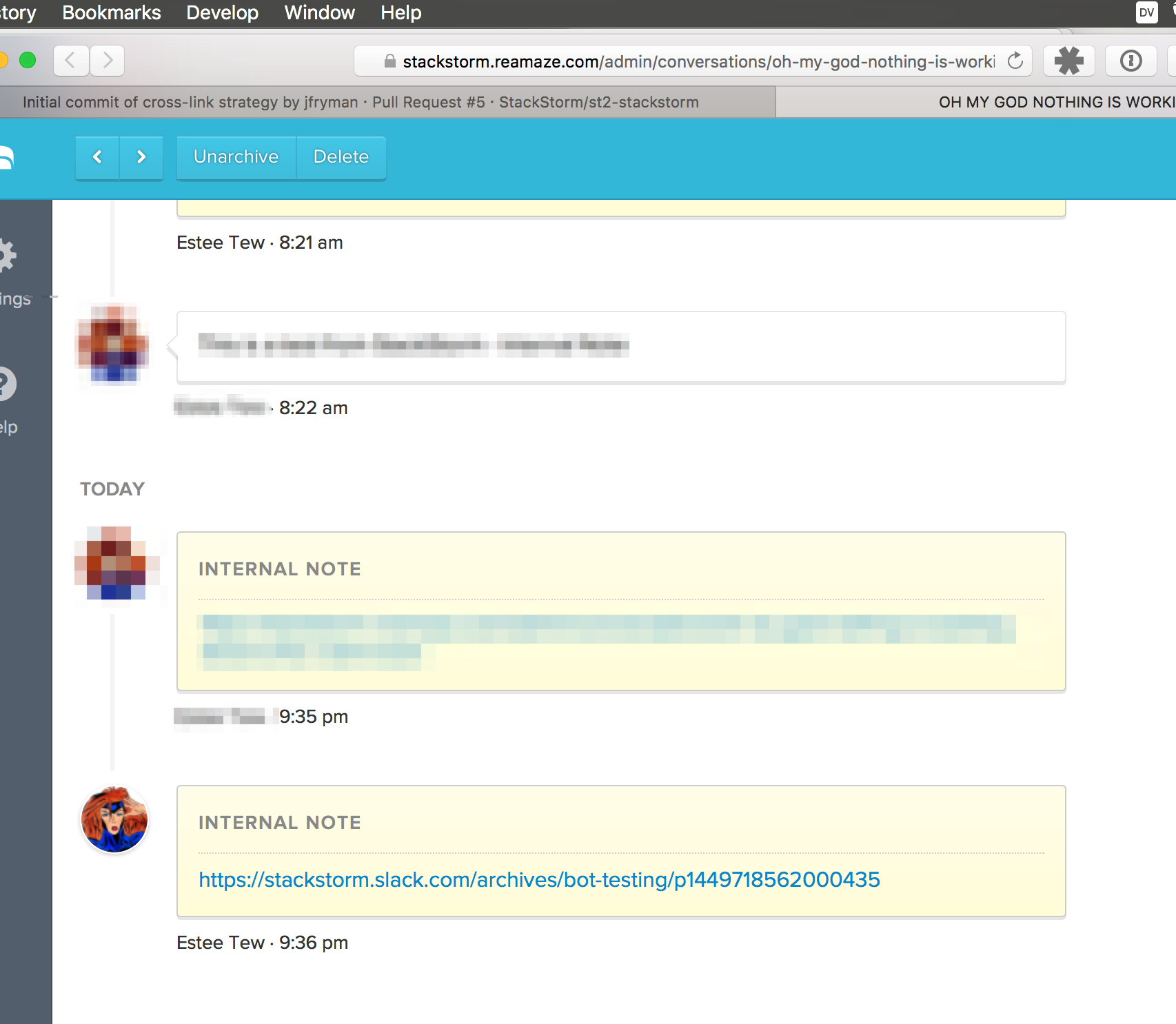
The next step actually happens in two tasks: sanitize_message and get_reamaze_slug. The immediate next step, sanitize_message, is necessary to clean up the output from Slack. In the message payload, URL data is sent to us as a special “escape sequence” which doesn’t do the rest of the actions much good. This action, detailed below, is simple enough to be reused in several other workflows. Again, take a look at the action itself The run() method in this python-runner task is the entry point from StackStorm, and this cleans up the text and returns it back as a plain URL which we can then pass to the next action, get_reamaze_slug. This returned information gets us what we need in order to call our final action, reamaze.create_message. We’re able to publish the permalink slug that was shared and discussed in chat. Now we know what is being discussed.
In this step, a the link is actually created. Here we are! The finish line! Woot! The only thing that is essential to do is to make sure we only set the note as an Internal Only note to avoid sending weird links to our friends. The next step is the crosslink_slack_to_reamaze action. At this point, we have all the data we need, so it’s just execution.
Permalink from Slack. Crosspost to reamaze
The premise is simple enough. Included in the upstream repository also includes examples for how to setup similar context mapping with StackStorm. Take a look at https://github.com/stackstorm-packs/st2-crosslink_chat_with_applications. Same process, code reuse, and the same end effect.
There are many more that will come up, but the key facter to address here is that it’s not difficult to put this together, and it’s not that difficult to change. And that’s ok. We’ll have questions to be answered, but being able to try something out super quickly was indeed satisfying. (In truth, the workflow went up faster than the blog. :P)
For many reasons, it is unfeasable to capture many fluid conversations in many different tools. The answer is not to move data around, but to leverage humans and provide them a helping hand. This is by no mean a solution, but it begins to provide less friction in the daily work. Over time, add enough of these friction reducers, and then suddenly… it’s no longer a panic. This also reinforces the idea that there is not a collection of systems, but rather a single system. The single company. The tools you selected are obviously necessary as we defined at the beginning, but tools should not be dictating the communication structures of your teams, but rather informing them. Removing the ability for silos to form allows data in both bits and ideas to flow and move around. This can even be expanded to do much more…
Until next time!